DF-Mamba: Deformable State Space Modeling for 3D Hand Pose Estimation in Interactions
Yifan Zhou1* Takehiko Ohkawa1,3* Guwenxiao Zhou1 Kanoko Goto1 Takumi Hirose1 Yusuke Sekikawa2 Nakamasa Inoue1
1Institute of Science Tokyo 2Denso IT Laboratory 3The University of Tokyo *Equal Contribution
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026
Abstract
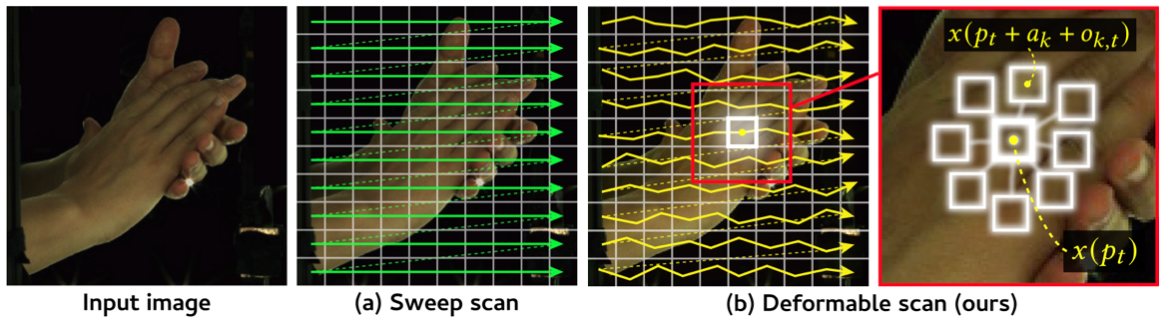
Modeling daily hand interactions often struggles with severe occlusions, such as when two hands overlap, which highlights the need for robust feature learning in 3D hand pose estimation (HPE). To handle such occluded hand images, it is vital to effectively learn the relationship between local image features (e.g., for occluded joints) and global context (e.g., cues from inter-joints, inter-hands, or the scene). However, most current 3D HPE methods still rely on ResNet for feature extraction, and such CNN's inductive bias may not be optimal for 3D HPE due to its limited capability to model the global context. To address this limitation, we propose an effective and efficient framework for visual feature extraction in 3D HPE using recent state space modeling (i.e., Mamba), dubbed Deformable Mamba (DF-Mamba). DF-Mamba is designed to capture global context cues beyond standard convolution through Mamba's selective state modeling and the proposed deformable state scanning. Specifically, for local features after convolution, our deformable scanning aggregates these features within an image while selectively preserving useful cues that represent the global context. This approach significantly improves the accuracy of structured 3D HPE, with comparable inference speed to ResNet-50. Our experiments involve extensive evaluations on five divergent datasets including single-hand and two-hand scenarios, hand-only and hand-object interactions, as well as RGB and depth-based estimation. DF-Mamba outperforms the latest image backbones, including VMamba and Spatial-Mamba, on all datasets and achieves state-of-the-art performance.
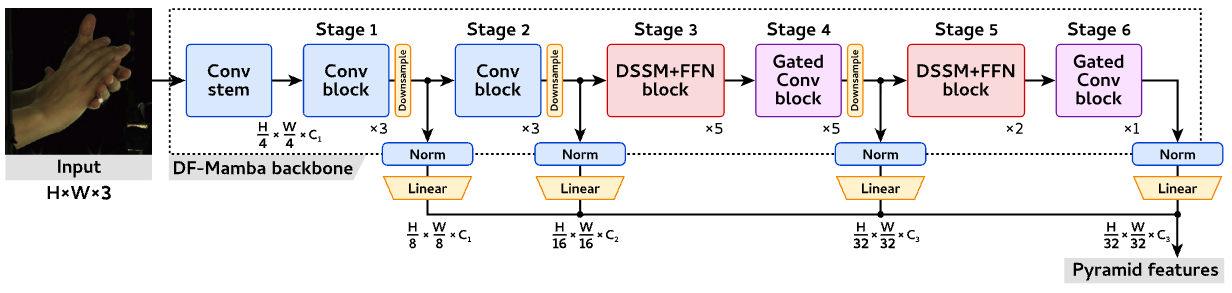
DF-Mamba Architecture
We design a tribrid architecture that integrates the DSSM blocks with conv blocks and gated conv blocks. This approach efficiently leverages the complementary strengths of different blocks by extracting features through convolution blocks at lower layers, while adaptively enhancing visual feature maps using DSSM blocks at higher layers.
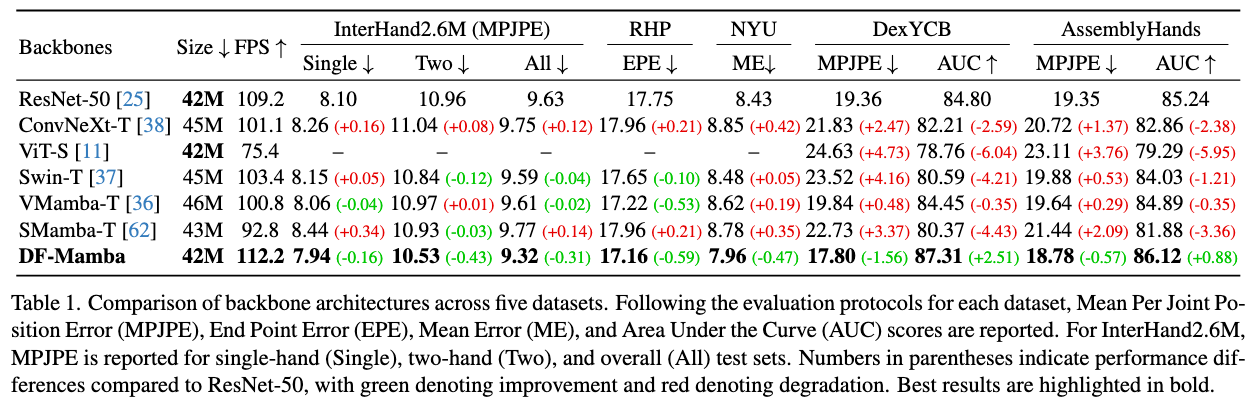
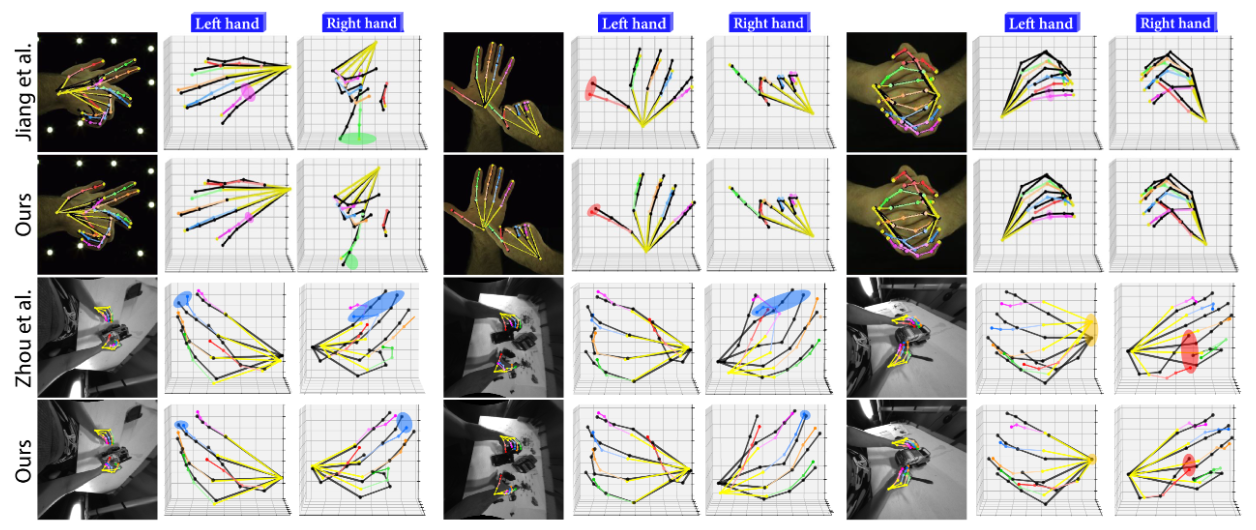
Results for 3D Hand Pose Estimation
We evaluate our approach by integrating representative 3D hand pose estimation frameworks and replacing their original backbones. Specifically, we adopt A2J-Transformer for InterHand2.6M, RHP, and NYU, and DetNet for DexYCB and AssemblyHands. Our proposed DF-Mamba consistently outperforms both vision transformer–based and Mamba-based backbones across all benchmarks. Moreover, DF-Mamba retains a model size and runtime comparable to ResNet-50, demonstrating its efficiency.
|
© Takehiko Ohkawa |